


Een paar jaar nadat Google aankondigde dat hun kennisgrafiek het mogelijk maakte om naar dingen te zoeken in plaats van naar strings, zijn kennisgrafieken en ontologieën in opmars bij ‘s werelds toonaangevende informatieorganisaties als middel om gegevens en kennis die ze nodig hebben om concurrerend te blijven, te integreren, te delen en te exploiteren. Maar wat is een kennisgrafiek precies en welke vorm en inhoud heeft deze in het geval van Textkernel? Welke aanpak wordt er gebruikt om deze op een schaalbare, tijdseffectieve manier op te bouwen, waarbij de kwaliteit hoog blijft? En, het allerbelangrijkste, welke voordelen levert het op voor de technologie en daarmee voor het bedrijf en de klanten van Textkernel? Dit zijn de belangrijkste vragen die Panos Alexopoulos, Lead Team Ontology Mining, in dit blogartikel probeert te beantwoorden. Door Panos Alexopoulos
Textkernel’s ontologie introduceren
Data Scientist is een (erg trendy) beroep en Hadoop is een vaardigheid die de meeste data scientists moeten hebben. Macro-economie en micro-economie zijn beide takken van de economie, terwijl de functietitel “Rechercheur” zowel een wetenschappelijk onderzoeker als een rechercheur bij de politie kan betekenen. Feiten zoals deze maken meestal deel uit van de domeinkennis die recruiters in hun dagelijkse routines gebruiken wanneer ze in cv’s en vacatures duiken om ze te begrijpen en te matchen. Maar niet noodzakelijkerwijs van computersystemen die hetzelfde proberen te doen. Dit resulteert meestal in suboptimale prestaties van cv’s en vacatures parsers en zoekmachines, omdat het gebrek aan domeinkennis deze systemen niet in staat stelt om echte concepten in plaats van strings te verwerken en daarover te redeneren. Textkernel’s softwaremodules hebben daarentegen wel toegang tot dergelijke kennis in de vorm van Textkernel’s ontologie, een grote kennisgrafiek die concepten en entiteiten over het HR- en recruitmentdomein definieert en met elkaar in verband brengt, zoals beroepen, vaardigheden, kwalificaties, onderwijsinstellingen, bedrijven enz. Via de ontologie kan een agent (mens of computersysteem) vragen beantwoorden als: – Wat voor soort entiteit is een bepaalde term/keyword (een vaardigheid, een beroep, een bedrijf enz.)? – Wat zijn de synoniemen en/of spellingsvarianten van een bepaalde entiteit in een bepaalde taal? – Is een entiteit breder of smaller dan een andere entiteit? (bijv. is java-ontwikkelaar een beperkter beroep dan softwareontwikkelaar?) – Wat zijn de belangrijkste vaardigheden voor een bepaald beroep? – Welke kwalificaties zijn belangrijk voor een bepaald beroep? – Wat zijn de typische banen die iemand met een bepaalde functietitel eerder heeft gehad (carrièrepad)? De “antwoorden” op deze vragen, de domeinkennis, worden gerepresenteerd en opgeslagen in de ontologie volgens een uniform schema met een duidelijke en goed gedocumenteerde semantiek. Elk concept heeft een unieke identifier (URI) en rijke taalkundige informatie (synoniemen en spellingsvarianten) in meerdere talen. Met deze informatie kunnen onze parsers termen en trefwoorden in cv’s en vacatures koppelen aan entiteiten en concepten met een zeer hoge nauwkeurigheid en dekking. Bovendien zijn concepten van hetzelfde type georganiseerd in taxonomische hiërarchieën waarbij de betekenis van een kindconcept beperkter is dan de betekenis van zijn ouderconcept (bijv. micro-economie beperkter dan economie). Concepten van hetzelfde of een ander type zijn ook op een associatieve manier aan elkaar gerelateerd via domeinspecifieke relaties (beroepen zijn bijvoorbeeld associatief gerelateerd aan de vaardigheden waarnaar ze het meest vragen op de arbeidsmarkt). Zowel hiërarchische als associatieve relaties stellen onze systemen in staat om a) ambigue termen te desambigueren bij het parsen van cv’s of vacatures en b) de semantische overeenkomst tussen deze termen te bepalen bij het zoeken of matchen. Een belangrijk kenmerk van Textkernel’s ontologie is ten slotte de koppeling met externe kennisgrafieken en taxonomieën/vocabulaires, zowel rekruteringsgerelateerde (bijv, ISCO, ESCO, O*NET, ROME etc.) en algemene (bijv. DBPedia, Eurovoc). Door onze eigen concepten in kaart te brengen in de externe kennisbronnen maken we a) de kennisstroom van onze ontologie naar deze bronnen en vice versa gemakkelijker, en b) de semantische interoperabiliteit met systemen die deze bronnen al gebruiken. Dit laatste is belangrijk omdat veel van deze modellen standaarden zijn (internationaal of in hun eigen land) en daarom veel gebruikt worden door onze klanten.

Textkernel ontologie bouwen en ontwikkelen
Het opbouwen en onderhouden van een grote kennisgrafiek over het wervingsdomein is een grote uitdaging, niet alleen omdat het domein vrij groot is, maar ook omdat het zeer heterogeen is (verschillende industrieën en zakelijke gebieden, talen, arbeidsmarkten, onderwijssystemen, enz. Een volledig handmatige aanpak (met menselijke experts die alle benodigde kennis definiëren) is te duur en niet schaalbaar, terwijl een volledig automatische aanpak (waarbij datamining- en machine-learningtechnieken worden gebruikt voor het extraheren van de kennis uit tekst) kan lijden onder lage kwaliteit. Om deze uitdaging het hoofd te bieden, baseren we de ontwikkeling van Textkernel’s ontologie op 3 principes:
Principe 1: Scope en structuurbepaling gebaseerd op bedrijfs- en systeembehoeften De scope en structuur/schema van Textkernel’s ontologie worden niet willekeurig bepaald, maar worden aangestuurd door de feitelijke gegevens die onze systemen moeten analyseren en verwerken, en door de manier waarop deze systemen de ontologie (kunnen) gebruiken om effectiever te worden. Dit betekent dat elk concept, attribuut en elke relatie in de ontologie niet alleen gerelateerd moet zijn aan het domein of de domeinen van de gegevens, maar ook een concrete rol moet spelen in de functionaliteit van onze systemen. Zo willen we bijvoorbeeld voor al onze ontologieconcepten lexicale termen en synoniemen hebben waarmee ze kunnen voorkomen in cv’s en vacatures, omdat deze kennis niet alleen wordt gebruikt door onze parsers, maar ook door onze search and match modules wanneer ze de zoekopdracht moeten uitbreiden. En onze prioriteit is om deze taalkundige informatie beschikbaar te hebben in ten minste Engels, Duits, Frans en Nederlands, aangezien dit de talen zijn van het merendeel van de gegevens die we verwerken. Terwijl gebruiken we zowel hiërarchische als associatieve conceptrelaties voor a) bladeren en navigeren door gegevens (bijv, de beroepentaxonomie in Jobfeed), b) uitbreiding van query’s (bijv. als we zoeken naar een economie-expert, kunnen we ook zoeken naar experts in de engere gebieden macro-economie en micro-economie), en c) desambiguering van entiteiten (bijv, van een vacature voor een onderzoeker kan worden bepaald of deze betrekking heeft op een wetenschappelijk onderzoeker of een politierechercheur op basis van de kennis van de vaardigheden waarmee deze twee beroepen verband houden).
Principe 2: Contentgeneratie op basis van datagestuurde ontologieontginning Terwijl het schema van Textkernel’s ontologie top-down, bedrijfs- en systeemgestuurd is opgebouwd (principe 1), is de inhoud (d.w.z.., de feitelijke concepten/entiteiten en attribuut-/relatiewaarden die het bevat) op een (semi-)automatische manier uit een verscheidenheid aan gestructureerde en ongestructureerde gegevensbronnen geëxtraheerd en in de ontologie opgenomen (ontology mining). Deze aanpak is nodig omdat de omvang (enkele duizenden entiteiten en concepten) en dynamiek van het recruitmentdomein een top-down, expert-gedreven aanpak onhaalbaar maken in termen van kosten en schaalbaarheid. Om deze aanpak te implementeren, hebben we intern relevante tools en pipelines ontwikkeld voor verschillende deeltaken van ontologie mining.
Enkele van deze deeltaken zijn:
T1: Ontdekken van (voorheen onbekende) entiteiten van een bepaald type (bijv. ontdekken dat java een vaardigheid is, Textkernel een bedrijf, of datawetenschapper een beroep).
T2: Mining synonyms, d.w.z., gegeven een ontologieconcept/entiteit, termen ontdekken die synoniem zijn (bijv. software engineer – softwareontwikkelaar, bedrijf – onderneming, etc.).
T3: Taxonomische relaties tussen concepten/entiteiten ontdekken, d.w.z., gegeven een ontologieconcept/entiteit, entiteiten ontdekken die een bredere/nauwere betekenis hebben dan het concept (bv. java smaller dan objectgeoriënteerd programmeren, IT-professional breder dan IT-consultant, enz: Mining associatieve binaire relaties, d.w.z., gegeven een associatieve binaire semantische relatie, ontdek paren van entiteiten die gerelateerd zijn via deze relatie (bijv, data scientist needs to know about hadoop, Textkernel has headquarters in Amsterdam, University of Amsterdam provides course in artificial intelligence, etc.). Voor al deze taken ontwikkelen en passen we state-of-the-art algoritmen en technieken voor machine learning en datamining toe.
Belangrijker is echter dat we elke taak aanpakken via een gedisciplineerd en gestructureerd proces dat de volgende stappen omvat:
Stap 1: We bepalen de exacte mijnbouwtaak en de doelsemantiek van de informatie die moet worden gedolven.
Stap 2: We identificeren en selecteren de ruwe gegevens die hoogstwaarschijnlijk de doelkennis bevatten (bijv. cv’s, vacatures, gebruikerslogboeken, enz.). Dit is belangrijk omdat de beste data voor een bepaalde taak niet altijd alle beschikbare data zijn!
Stap 3: We identificeren bestaande ontologische kennis (intern of extern) die nuttig kan zijn voor de taak. Deze kennis kan nuttig zijn voor a) het opstarten van dataverzameling, b) het creëren van kenmerken voor machine-learning algoritmen, c) het redeneren over de uitvoer van het (de) mijnbouwalgoritme(s), en d) het implementeren van heuristieken.
Stap 4: We ontwerpen/implementeren een aangepaste mijnbouwpijplijn die optimaal is voor de specifieke taak en semantiek. Dit betekent het selecteren en orkestreren van de meest geschikte algoritmen/tools voor de taak en, indien nodig, het toevoegen van mensen in de lus (zie principe 3)
Stap 5: We evalueren de resultaten en het proces zowel vanuit een algoritmisch perspectief als vanuit het perspectief van ontologieconstructie. Dit betekent dat we niet alleen meten hoe nauwkeurig en volledig het proces is (precisie/herinnering), maar ook hoe snel en kosteneffectief we een bevredigende ontologie voor onze doelen krijgen.
Principe 3: Mens in de lus voor kwaliteitsborging en voortdurende verbetering Zelfs de beste automatische ontologie-miningalgoritmen zijn gevoelig voor een bepaalde mate van onnauwkeurigheid die, afhankelijk van de concrete subtaak, aanzienlijk kan zijn. Daarom nemen we, om de hoogst mogelijke kwaliteit voor Textkernel’s ontologie te garanderen, menselijke oordelen op in het ontginningsproces, zodat we kunnen omgaan met gevallen waarin de algoritmen niet zeker of betrouwbaar genoeg zijn met betrekking tot hun eigen oordelen. Deze menselijke beoordelingen vullen niet alleen de kwaliteit van de algoritmen aan en beoordelen deze, maar ze worden ook teruggekoppeld naar de algoritmen om ze “slimmer” te maken en te helpen verbeteren. Op die manier wordt de constructie en evolutie van de ontologie een opwaartse spiraal die schaalbaar is.
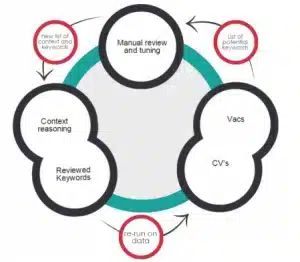
Het venijn zit in de details
In de vorige paragrafen heb ik een overzicht gegeven van Textkernel’s ontologie, het gebruik ervan binnen het bedrijf en het proces dat we volgen voor de ontwikkeling ervan. In volgende posts zal ik dieper ingaan op de “duivelse” details van enkele van de zeer uitdagende taken die bij dit laatste proces komen kijken, zoals bijvoorbeeld de automatische ontdekking van nieuwe vaardigheden of de detectie van synoniemen.
Over de auteur
Panos Alexopoulos is de Lead van het Ontology Mining Team bij Textkernel, verantwoordelijk voor de ontwikkeling, het beheer en de evolutie van de kennisgrafiek van het bedrijf voor het HR- en recruitmentdomein. Hij is geboren en getogen in Athene, Griekenland, heeft een PhD in Data and Knowledge Engineering van de Nationale Technische Universiteit van Athene, en hij heeft meer dan 10 jaar gecombineerde academische en industriële ervaring op het gebied van semantische technologieën en knowledge engineering. Omdat hij een gulzige lezer is, gebruikt hij zijn vrije tijd om op jacht te gaan naar nieuwe en oude boeken, in elke plaats die hij bezoekt en in elke taal die hij kan (of niet kan) begrijpen.

