

Voor Jobs Data, Textkernel’s real-time database voor arbeidsmarktanalyse, crawlen we het web af op zoek naar online vacatures. Natuurlijk brengt het waarborgen van de hoge kwaliteit van deze database veel technische uitdagingen met zich mee. Een daarvan is het detecteren van duplicaten van vacatures. In deze blogpost leggen we uit hoe Textkernel dit probleem oplost.

De gemiddelde online vacature heeft veel duplicaten
Als je met grote hoeveelheden webgegevens werkt, kom je vroeg of laat het probleem van dubbele inhoud tegen. Veel webpagina’s zijn niet uniek: een artikel van Google suggereert dat ongeveer 30% van de webpagina’s bijna-duplicaten zijn. In Jobs Data, waar we online vacatures in acht landen spideren, is dit probleem nog prominenter: we ontdekten dat een gemiddelde vacature 2 tot 5 keer opnieuw wordt geplaatst (afhankelijk van het land), waardoor de fractie duplicaten oploopt tot 50-80%. Dit is niet verrassend: bedrijven adverteren hun vacatures zo breed mogelijk om meer goede sollicitanten aan te trekken: op bedrijfssites, op algemene en gespecialiseerde vacaturebanken, via uitzendbureaus, enz. Daarom is het identificeren en groeperen van dubbele advertenties een essentiële stap in onze gegevensverwerking.
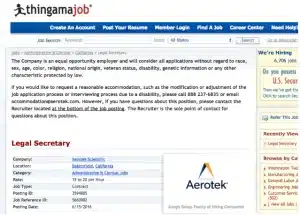
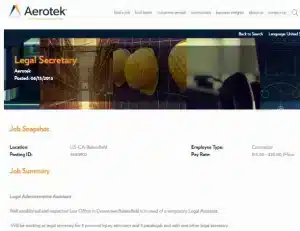
Bijna-dubbele vacatureadvertenties zijn zelden identiek: wanneer een advertentie op een andere site wordt geplaatst, wordt de tekst vaak geherstructureerd, ingekort of uitgebreid en worden de metadata vaak aangepast aan het datamodel van de site. Bekijk de twee onderstaande advertenties voor dezelfde vacature:
Tekstuele gelijkenis
Efficiënte methoden voor het vinden van vergelijkbare webpagina’s zijn bijna net zo oud als het web zelf: het baanbrekende artikel Syntactic clustering of the web van A. Broder et al. verscheen in 1997. In Jobs Data gebruiken we een klassieke benadering op basis van shingling en min-wise permutaties. Zoals we hieronder laten zien, kan een relatief eenvoudige implementatie gemakkelijk tientallen miljoenen documenten verwerken. Voor datasets met miljarden documenten is een geavanceerdere implementatie en/of een andere methode nodig: zie de blogpost Near-Duplicate Detection voor een overzicht en de paper Detecting Near-Duplicates for Web Crawling voor meer informatie. Met shingling zetten we elk tekstdocument om in een verzameling van alle reeksen (shingles) van opeenvolgende woorden die in het document voorkomen. Als we bijvoorbeeld 6-woordreeksen beschouwen voor de tekst “Een gerenommeerd en gerespecteerd advocatenkantoor in het centrum van Bakersfield is op zoek naar een tijdelijke juridisch assistent …”, bestaan de shingles uit: – “Een gerenommeerd en gerespecteerd advocatenkantoor” – “Een gerenommeerd en gerespecteerd advocatenkantoor in het centrum van Bakersfield” – “en gerespecteerd advocatenkantoor in het centrum van Bakersfield” enz. We kunnen de tekstuele gelijkenis tussen twee documenten meten als de overlap tussen hun sets shingles. Voor onze voorbeeldadvertenties “Juridisch secretaresse” hebben de twee documenten 179 van de in totaal 484 shingles gemeen, wat een overeenkomst van 37% oplevert. Dit lijkt misschien laag, gezien het feit dat de functiebeschrijvingen bijna identiek zijn: het is voornamelijk te wijten aan de verschillende opmaak van metadata (locatie, bedrijfsnaam, telefoon) en ontbrekende tekst over gelijke kansen. Het is duidelijk dat voor vacatures het gebruik van een eenvoudige gelijkenisdrempel om te beslissen of twee advertenties duplicaten zijn, niet voldoende zou zijn.
Gelijksoortige documenten efficiënt vinden
Om het opslaan en vergelijken van honderden shingles voor elk document te vermijden, passen we als volgt een lokaliteitsgevoelig hashing-schema toe. Eerst zetten we elke shingle van een document om in een geheel getal van 64 bits met behulp van een goede hashingfunctie. Laten we deze integers shingle hashes noemen. We nemen een vaste willekeurige geheel getal permutatie, passen deze toe op alle shingle hashes van het document en nemen de kleinste waarde – dit is de eerste waarde die we opslaan. We herhalen dit M keer met verschillende vaste willekeurige permutaties, om een lijst van M gehele getallen te krijgen: dit noemen we de schets van het document. Het blijkt dat we, om de gelijkenis van twee documenten te schatten, alleen het aantal overeenkomende gehele getallen in hun schetsen hoeven te tellen. Dit betekent dat we slechts M gehele getallen hoeven op te slaan voor elk document. Door de juiste waarde voor M te kiezen, kunnen we een goede afweging maken tussen de nauwkeurigheid van de schatting en de opslagvereisten. Hoe slaan we documentschetsen op om snel vergelijkbare documenten op te zoeken? We gebruiken een veelgebruikte techniek: een omgekeerde index. We berekenen schetsen voor alle documenten in onze dataset en voor elk integer dat we waarnemen, slaan we een lijst op van documenten waarvan de schetsen dit integer bevatten. Om gelijksoortige documenten te vinden voor een nieuwe invoer, hoeven we alleen documentenlijsten samen te voegen voor de M gehele getallen in de schets. Tijd- en geheugenefficiënt beheer van dergelijke indexen is waar Elasticsearch erg goed in is, dus gebruiken we het om onze schetsen te indexeren en mogelijke bijna-duplicaten op te halen. We werken de index voortdurend bij als nieuwe documenten worden gespiderd in Jobs Data.
Specifiek voor het ontdubbelen van vacatureadvertenties
Zoals ik hierboven heb besproken, gebruiken we shingling, min-wise permutation hashing en inverted indexing om vacatures te vinden die tekstueel lijken op een nieuw invoerdocument. Voor detectie van bijna-duplicaten voor algemene doeleinden is dit vaak alles wat nodig is: een eenvoudige drempelwaarde voor tekstovereenkomst tussen de invoer en de kandidaten is voldoende om te beslissen of de invoer een duplicaat is. Voor vacatures is zo’n op drempels gebaseerde aanpak niet voldoende: zoals we in ons voorbeeld hebben gezien, kunnen echte duplicaten een overeenkomst van wel 37% hebben. In Jobs Data vullen we tekstgebaseerde retrieval aan met nog een paar trucs: – We passen machine learning en regelgebaseerde technieken toe om irrelevante inhoud te verwijderen (boilerplate-tekst, navigatie, banners, advertenties, enz.) – We gebruiken onze semantische parser die speciaal is getraind voor personeelsadvertenties om tekstsecties te identificeren die de functieomschrijving en de vereisten van de kandidaat bevatten (in tegenstelling tot de algemene beschrijving van het adverterende bedrijf, die vaak wordt herhaald in veel ongerelateerde personeelsadvertenties van het bedrijf) – Voor elke nieuwe personeelsadvertentie gebruiken we shingling zoals hierboven beschreven om kandidaten te vinden met een aanzienlijke tekstoverlap. – We trainen een classifier om te voorspellen of een gegeven invoer en een opgehaalde kandidaat inderdaad vacatures zijn van dezelfde baan. De classifier baseert zich op de tekstoverlap en de overeenkomst tussen andere eigenschappen van de vacatures, zoals geëxtraheerd door onze semantische parser: organisatienaam, beroepscategorie, contactgegevens, enzovoort. Hoe nauwkeurig is het systeem dat ik hierboven heb geschetst? Vindt het alle duplicaten? Groepeert het postings die geen duplicaten zijn? Een kort antwoord zou zijn dat het systeem “redelijk goed is, ongeveer 90%”. Een langer antwoord zou een bespreking vereisen van de vele mogelijke manieren om een dergelijk systeem te evalueren – iets wat ik in een vervolgpost zal doen. Enkele nuttige links – xxhash: een goede hashingbibliotheek voor Python – Integer hashfuncties: het mengen van omkeerbare hashfuncties door Thomas Wang die kunnen worden gebruikt om pseudowillekeurige permutaties te construeren.
