

Einige Jahre nachdem Google angekündigt hat, dass ihr Knowledge Graph die Suche nach Dingen und nicht nach Zeichenketten ermöglicht, haben Knowledge Graphs und Ontologien in den weltweit führenden Organisationen an Bedeutung gewonnen. Aber was genau ist ein Knowledge Graph und welche Form und welchen Inhalt hat er im Fall von Textkernel? Welcher Ansatz wird verwendet, um ihn skalierbar, zeitsparend und in hoher Qualität zu erstellen? Und, was am wichtigsten ist, welche Vorteile bringt er der Technologie und damit dem Geschäft und den Kunden von Textkernel?
Dies sind die Schlüsselfragen, die Panos Alexopoulos, Lead Team Ontology Mining, in diesem Blog-Artikel zu beantworten versucht.
Einführung in die Ontologie von Textkernel
Data Scientist ist ein (sehr trendiger) Beruf und Hadoop ist eine Fähigkeit, über die die meisten Data Scientists verfügen müssen. Makroökonomie und Mikroökonomie sind beide Zweige der Wirtschaftswissenschaften, während die Berufsbezeichnung „Ermittler“ sowohl einen wissenschaftlichen Forscher als auch einen polizeilichen Ermittler bedeuten kann. Fakten wie diese sind in der Regel Teil des Fachwissens, das Personalvermittler in ihrer täglichen Arbeit nutzen, wenn sie sich mit Lebensläufen und Stellenangeboten befassen und versuchen, diese zu verstehen und zuzuordnen. Aber nicht unbedingt von Computersystemen, die dasselbe versuchen.
Dies führt typischerweise zu einer suboptimalen Leistung von Lebenslauf- und Stellenangebots-Parsern sowie von Suchmaschinen, da diese Systeme aufgrund des fehlenden Domänenwissens nicht in der Lage sind, reale Konzepte anstelle von Zeichenketten zu verarbeiten und darüber nachzudenken. Die Softwaremodule von Textkernel hingegen haben Zugang zu solchem Wissen in Form der Ontologie von Textkernel, einem großen Knowledge Graphen, der Konzepte und Entitäten aus dem Personal- und Recruitingbereich definiert und miteinander in Beziehung setzt, wie z.B. Berufe, Fähigkeiten, Qualifikationen, Bildungseinrichtungen, Unternehmen usw. Mithilfe der Ontologie kann ein Agent (Mensch oder Computersystem) Fragen wie die folgenden beantworten:
– Welche Art von Entität ist ein bestimmter Begriff/Schlüsselwort (eine Fähigkeit, ein Beruf, ein Unternehmen usw.)?
– Welche Synonyme und/oder Schreibvarianten gibt es für eine bestimmte Entität in einer bestimmten Sprache?
– Ist eine Entität umfassender oder enger als eine andere Entität? (z.B. ist Java-Entwickler ein engerer Beruf als Software-Entwickler?
– Was sind die wichtigsten Fähigkeiten für einen bestimmten Beruf?
– Welche Qualifikationen sind für einen bestimmten Beruf wichtig?
– Was sind die typischen Berufe, die jemand mit einer bestimmten Berufsbezeichnung bisher ausgeübt hat (Karriereweg)?

Aufbau und Weiterentwicklung der Ontologie von Textkernel
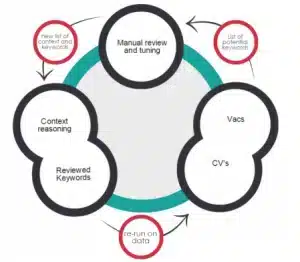
Die Erstellung und Pflege eines großen Knowledge Graph über den Bereich Personalbeschaffung ist eine große Herausforderung, nicht nur, weil der Bereich recht groß ist, sondern auch, weil er sehr heterogen ist (verschiedene Branchen und Geschäftsbereiche, Sprachen, Arbeitsmärkte, Bildungssysteme usw.) und sich ändert ein sehr schnelles Tempo. Ein vollständig manueller Ansatz (bei dem menschliche Experten das gesamte erforderliche Wissen definieren) ist zu kostspielig und nicht skalierbar, während ein vollständig automatischer Ansatz (bei dem Data-Mining und Techniken des maschinellen Lernens zum Extrahieren des Wissens aus Texten verwendet werden) möglicherweise an schlechter Qualität leidet. Um dieser Herausforderung zu begegnen, basieren wir die Entwicklung der Textkernel-Ontologie auf drei Prinzipien: Prinzip 1: Umfangs- und Strukturdefinition basierend auf Geschäfts- und Systemanforderungen< br> Umfang und Struktur/Schema der Ontologie von Textkernel werden nicht willkürlich bestimmt, sondern werden von den tatsächlichen Daten bestimmt, die unsere Systeme analysieren und verarbeiten müssen, sowie von der Art und Weise, wie diese Systeme die Ontologie nutzen (können), um effektiver zu werden. Das bedeutet, dass jedes in der Ontologie definierte Konzept, Attribut und jede Beziehung nicht nur mit der/den Domäne(n) der Daten in Zusammenhang stehen muss, sondern auch eine konkrete Rolle in der Funktionalität unserer Systeme erfüllen muss. Somit gilt: Beispielsweise möchten wir für alle unsere Ontologiekonzepte lexikalische Begriffe und Synonyme haben, mit denen sie in Lebensläufen und Stellenangeboten erscheinen können, da dieses Wissen nicht nur von unserer verwendet wird Parser aber auch durch unsere Suche und Übereinstimmung Module, wenn sie eine Abfrageerweiterung durchführen müssen. Und unsere Priorität ist es, diese sprachlichen Informationen mindestens in Englisch, Deutsch, Französisch und Niederländisch verfügbar zu haben, da dies die Sprachen der meisten von uns verarbeiteten Daten sind. Gleichzeitig nutzen wir beide Sprachen hierarchische und assoziative Konzeptbeziehungen für a) Durchsuchen und Navigieren von Daten (z. B. die Berufstaxonomie in Jobfeed), b) Abfrageerweiterung (z. B. könnten wir bei der Suche nach einem Wirtschaftsexperten auch nach Experten in den engeren Bereichen der Makroökonomie suchen und Mikroökonomie) und c) zur Entitätsdisambiguierung (z. B. könnte bei einer Stellenausschreibung, bei der ein Ermittler gesucht wird, anhand der Kenntnisse über die Fähigkeiten, mit denen diese beiden Berufe zusammenhängen, festgestellt werden, ob es sich um einen wissenschaftlichen Forscher oder einen polizeilichen Ermittler handelt). < br> Prinzip 2: Inhaltsgenerierung basierend auf datengesteuertem Ontologie-Mining Während das Schema der Textkernel-Ontologie von oben nach unten aufgebaut ist, geschäfts- und systemgesteuert Auf diese Weise (Prinzip 1) wird sein Inhalt (d. h. die darin enthaltenen tatsächlichen Konzepte/Entitäten und Attribut-/Relationswerte) auf (halb-)automatische Weise aus einer Vielzahl strukturierter und unstrukturierter Datenquellen extrahiert und in die Ontologie integriert (Ontologie-Mining) . Dieser Ansatz ist notwendig, da die Größe (mehrere Tausend Einheiten und Konzepte) und die Dynamik des Rekrutierungsbereichs einen von oben nach unten gerichteten, von Experten gesteuerten Ansatz im Hinblick auf Kosten und Skalierbarkeit undurchführbar machen. Um diesen Ansatz umzusetzen, Wir haben intern relevante Tools und Pipelines für verschiedene Teilaufgaben des Ontology Mining entwickelt. Einige dieser Unteraufgaben sind: T1: Entdecken (bisher unbekannter) Entitäten eines bestimmten Typs (z. B. entdecken, dass Java eine Fähigkeit, Textkernel ein Unternehmen oder Datenwissenschaftler ein Beruf ist). T2: Synonyme abbauen, d. h. anhand eines gegebenen Ontologiekonzepts/einer gegebenen Ontologiebegriffe Begriffe entdecken, die dafür synonym sind (z. B. Softwareentwickler – Softwareentwickler, Unternehmen – Unternehmen usw.). T3: Taxonomische Beziehungen zwischen Konzept und Entität abbauen, d. h. bei einem gegebenen Ontologiekonzept/einer gegebenen Ontologieentität Entitäten entdecken, die eine breitere/engere Bedeutung haben als diese (z. B. Java enger als objektorientierte Programmierung, IT-Experte breiter als IT-Berater usw.). T4: Mining assoziativer binärer Beziehungen, d. h. bei gegebener assoziativer binärer semantischer Beziehung Paare von Entitäten entdecken, die dadurch in Beziehung stehen (z. B. muss ein Datenwissenschaftler über Hadoop Bescheid wissen, Textkernel hat seinen Hauptsitz in Amsterdam, die Universität Amsterdam bietet Kurse in künstlicher Intelligenz an usw.). Für all diese Aufgaben entwickeln und wenden wir modernste Algorithmen und Techniken für maschinelles Lernen und Data Mining an siehe zum Beispiel Maartens Blogbeitrag über Deep Learning zur Jobnormalisierung Noch wichtiger ist jedoch, dass wir jede Aufgabe diszipliniert und strukturiert angehen Prozess, der die folgenden Schritte umfasste: Schritt 1: Wir bestimmen die genaue Mining-Aufgabe und die Zielsemantik der zu extrahierenden Informationen. Schritt 2: Wir identifizieren und wählen die Rohdaten aus, die die Daten am wahrscheinlichsten enthalten Zielwissen (z.B. Lebensläufe, offene Stellen, Benutzerprotokoll
Der Teufel steckt im Detail
In den vorangegangenen Abschnitten habe ich einen Überblick über die Ontologie von Textkernel, ihre Verwendung innerhalb des Unternehmens und den Prozess, den wir bei ihrer Entwicklung verfolgen, gegeben. In den folgenden Beiträgen werde ich auf die “teuflischen” Details einiger der höchst anspruchsvollen Aufgaben eingehen, die mit dem letztgenannten Prozess verbunden sind, wie z. B. die automatische Entdeckung neuer Fähigkeiten oder die Erkennung synonymer Begriffe.
Über den Autor
Panos Alexopoulos ist Leiter des Ontology Mining Teams bei Textkernel und verantwortlich für die Entwicklung, Verwaltung und Weiterentwicklung des Wissensgraphen des Unternehmens für den Bereich HR und Recruiting. Geboren und aufgewachsen in Athen, Griechenland, hat er einen Doktortitel in Data and Knowledge Engineering von der Nationalen Technischen Universität Athen und verfügt über mehr als 10 Jahre kombinierte akademische und industrielle Erfahrung in den Bereichen semantische Technologien und Knowledge Engineering. Als unersättlicher Leser nutzt er seine Freizeit, um neue und alte Bücher zu jagen, an jedem Ort, den er besucht, und in jeder Sprache, die er verstehen kann (oder auch nicht).



