
Für Jobs Data, die Echtzeit-Datenbank von Textkernel zur Arbeitsmarktanalyse, durchsuchen wir das Internet nach Online-Stellenanzeigen. Die Sicherstellung der hohen Qualität dieser Datenbank bringt natürlich viele technische Herausforderungen mit sich. Eine davon ist die Erkennung von Duplikaten von Stellenanzeigen. In diesem Blogbeitrag erklären wir, wie Textkernel dieses Problem löst.

Die durchschnittliche Online-Stellenanzeige enthält viele Duplikate
Wenn Sie mit großen Mengen von Webdaten arbeiten, stoßen Sie früher oder später auf das Problem doppelter Inhalte. Viele Webseiten sind nicht einzigartig: ein Google-Papier legt nahe, dass etwa 30 % der Webseiten nahezu doppelt vorhanden sind.
In Jobs Data, dem Tool, mit dem wir Online-Stellenanzeigen in acht Ländern erfassen, ist dieses Problem sogar noch ausgeprägter: Wir haben herausgefunden, dass eine durchschnittliche Stellenanzeige 2 bis 5 Mal (je nach Land) neu veröffentlicht wird, was den Anteil der Duplikate auf 50-80 % ansteigen lässt. Das ist nicht verwunderlich: Unternehmen schreiben ihre Stellen so breit wie möglich aus, um mehr gute Bewerber anzuziehen: auf Unternehmenswebsites, in allgemeinen und speziellen Stellenbörsen, über Staffing-Agenturen usw. Die Identifizierung und Gruppierung doppelter Anzeigen ist daher ein wesentlicher Schritt in unserer Datenverarbeitung.
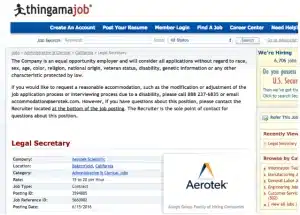
Nahezu identische Stellenanzeigen sind selten identisch: Wenn eine Anzeige auf einer anderen Website veröffentlicht wird, wird der Text oft umstrukturiert, gekürzt oder erweitert, und die Metadaten werden oft geändert, um dem Datenmodell der Website zu entsprechen.
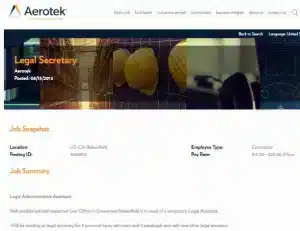
Textliche Ähnlichkeit
Effiziente Methoden zum Auffinden ähnlicher Webseiten sind fast so alt wie das Web selbst: 1997 erschien die bahnbrechende Arbeit Syntactic clustering of the web von A. Broder et al. In Jobs Data verwenden wir einen klassischen Ansatz, der auf Shingling und minimalen Permutationen basiert.
Wie wir weiter unten zeigen, kann eine relativ einfache Implementierung leicht mit mehreren zehn Millionen Dokumenten umgehen. Für Datensätze mit Milliarden von Dokumenten ist eine ausgefeiltere Implementierung und/oder eine andere Methode erforderlich: siehe den Blogbeitrag Near-Duplicate Detection für einen Überblick und das Paper Detecting Near-Duplicates for Web Crawling für Details. Beim Shingling konvertieren wir jedes Textdokument in eine Menge aller Sequenzen (Shingles) von aufeinanderfolgenden Wörtern, wie sie im Dokument vorkommen.
Betrachten wir zum Beispiel 6-Wort-Sequenzen für den Text “Gut etablierte und angesehene Anwaltskanzlei in der Innenstadt von Bakersfield sucht einen befristeten Rechtsassistenten …”, so umfassen die Shingles:
– “Gut etablierte und angesehene Anwaltskanzlei”
– “etablierte und angesehene Anwaltskanzlei in”
– “und angesehene Anwaltskanzlei in der Innenstadt” usw.
Wir können die Textähnlichkeit zwischen zwei Dokumenten als die Überschneidung zwischen ihren Schindelmengen messen. In unserem Beispiel der “Legal secretary”-Anzeigen überschneiden sich 179 von insgesamt 484 Shingles, was eine Ähnlichkeit von 37 % ergibt. Dies mag gering erscheinen, wenn man bedenkt, dass die Stellenbeschreibungen nahezu identisch sind: Dies ist hauptsächlich auf die unterschiedliche Formatierung der Metadaten (Standort, Firmenname, Telefon) und den fehlenden Text zur Chancengleichheit bei der Beschäftigung zurückzuführen. Es ist klar, dass bei Stellenanzeigen eine einfache Ähnlichkeitsschwelle nicht ausreicht, um zu entscheiden, ob es sich bei zwei Anzeigen um Duplikate handelt.
Effiziente Suche nach ähnlichen Dokumenten
Besonderheiten bei der Deduplizierung von Stellenanzeigen
Wie bereits erwähnt, verwenden wir Shingling, Min-wise Permutation Hashing und Inverted Indexing, um Stellenanzeigen zu finden, die einem neuen Eingabedokument textlich ähnlich sind. Für die allgemeine Erkennung von Beinahe-Duplikaten reicht dies oft aus: ein einfacher Schwellenwert für die Textähnlichkeit zwischen der Eingabe und den Kandidaten reicht aus, um zu entscheiden, ob es sich bei der Eingabe um ein Duplikat handelt. Für Stellenanzeigen ist ein solcher schwellenwertbasierter Ansatz nicht ausreichend: Wie wir in unserem Beispiel gesehen haben, können echte Duplikate eine Ähnlichkeit von nur 37 % aufweisen.
In Jobs Data ergänzen wir die textbasierte Suche mit ein paar weiteren Tricks:
– Wir wenden maschinelles Lernen und regelbasierte Techniken an, um irrelevante Inhalte zu entfernen (Textbausteine, Navigation, Banner, Anzeigen usw.)
– Wir verwenden unsere semantischen Parser, der speziell für Stellenanzeigen trainiert wurde, um Textabschnitte zu identifizieren, die Stellenbeschreibungen und Anforderungen an die Bewerber enthalten (im Gegensatz zur allgemeinen Beschreibung des inserierenden Unternehmens, die oft in vielen anderen Stellenanzeigen des Unternehmens wiederholt wird)
– Für jede neue Stellenanzeige verwenden wir das oben beschriebene Shingling, um Kandidaten mit erheblichen Textüberschneidungen zu finden.
– Wir trainieren einen Klassifikator, um vorherzusagen, ob es sich bei einer gegebenen Eingabe und einem abgerufenen Kandidaten tatsächlich um ein und dieselbe Stellenanzeige handelt. Der Klassifikator stützt sich auf die Textüberschneidungen und die Übereinstimmung zwischen anderen Eigenschaften der Stellenausschreibungen, die von unserem semantischen Parser extrahiert wurden: Name des Unternehmens, Berufskategorie, Kontaktinformationen usw.
Wie genau ist das oben beschriebene System? Findet es alle Duplikate? Fasst es Beiträge zusammen, die keine Duplikate sind? Eine kurze Antwort würde lauten, dass das System “ziemlich gut ist, zu etwa 90 %”. Eine längere Antwort würde eine Diskussion vieler möglicher Wege zur Bewertung eines solchen Systems erfordern – etwas, das ich in einem Folgebeitrag tun werde.
Ein paar nützliche Links
– xxhash: eine gute Hash-Bibliothek für Python
– Ganzzahlige Hash-Funktionen: mischbare reversible Hash-Funktionen von Thomas Wang, die zur Konstruktion pseudo-zufälliger Permutationen verwendet werden können


